Overview
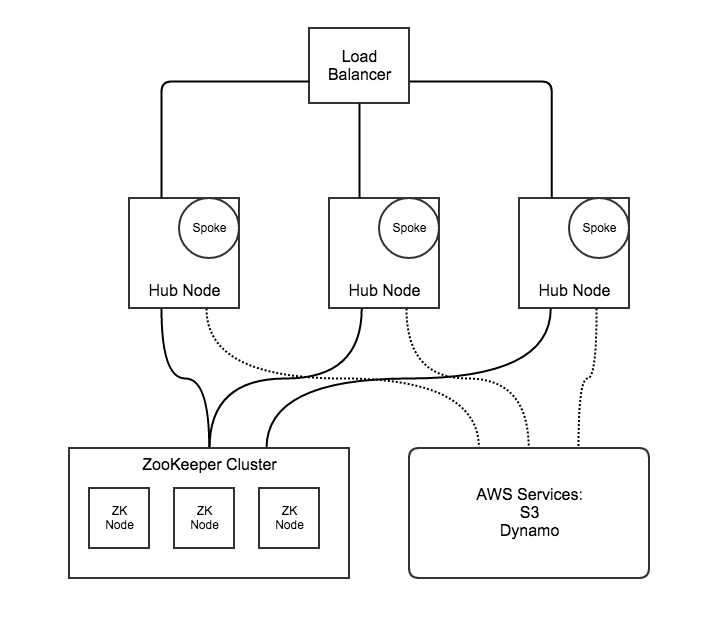
A standard hub installation requires:
- A load balancer. We use HAProxy
- A ZooKeeper Cluster
- At least 2 servers with local disk for the Hub and Spoke
- Credentials for access to S3 and DynamoDB in AWS
Hub Servers
At FlightStats, we have run hub clusters with AWS instances ranging from t2.small (1 core, 2GB RAM, 10 GB disk) to m4.xlarge (4 cores, 16GB RAM, 70 GB disk), depending on the requirements.
Quantity
The minimum requirement for a fault tolerant cluster is two servers, which provides a single redundancy.
FlightStats typically uses 3 instances, so we always have a backup during rolling restarts. This also means that during a failure scenario, the load is still divided between two instances.
A hub cluster could be larger than 3 instances. The hub would need to be modified for Spoke performance to scale linearly with larger clusters.
Spoke disk and memory
To get the best performance out of Spoke, instance memory should be sized so that all of Spoke’s data will fit within the Operating System’s File System cache.
Spoke should have dedicated disk to provide consistent performance. The disk needs to be sized for the Spoke cache time, which defaults to 60 minutes. Spoke compresses payloads by default.
Timing
For correct behavior in the Sequential Write Use Case, hub servers need system time to be precise within the cluster (not necessarily accurate) https://github.com/flightstats/hub/wiki/Hub-NTP-Settings
Configuration
Example config files for the hub, logback and start script
S3 Bucket
The hub requires a S3 bucket to be created ahead of time. The S3 bucket name is {app.name}-{s3.environment} from hub.properties
AWS credentials
If your cluster is running in EC2, the hub will automatically use the IAM roles to access S3 and Dynamo.
Otherwise, specify the location of your credentials with the property aws.credentials.
The dynamo-prefix is app.name-app.environment
The following are the permissions you need to set:
"Statement": [
{
"Sid": "Stmt1391722720000",
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::<s3-bucket>/*"
]
},
{
"Sid": "Stmt1391722763000",
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::<s3-bucket>"
]
},
{
"Sid": "Stmt1391722978000",
"Effect": "Allow",
"Action": [
"dynamodb:*"
],
"Resource": [
"arn:aws:dynamodb:us-west-2:<account-id>:table/<dynamo-prefix>-*"
]
}
]
ZooKeeper Servers
The hub is designed to use ZooKeeper lightly, and therefore these servers can be smaller than the hub servers. Our hub clusters share the ZooKeeper cluster within the same environment, for example, we run two Hub clusters in US-East production, and they both utilize a single ZooKeeper cluster. The three ZooKeeper instances are m3.mediums. In non-production environments we use t2.smalls and t2.micros.
For running on your local machine, the hub supports using an in-process ZooKeeper by default with the property runSingleZookeeperInternally=singleNode in
hub.properties